 Posted By :
liamjtolentino
31 Mar
Posted By :
liamjtolentino
31 Mar
AI is Going in the Wrong Direction
This post is gonna be a lot more technical than my usual ones, but don’t get mistaken because this is still just me venting my thoughts on a topic. In no way should this be treated as an academic source or anything like that. I just want to use my knowledge on machine learning and AI to voice my thought on the current direction we’re going with AI and why it’s not what anyone expects.
A Brief Overview (what even is AI?)
To begin, I would like to explain some things about AI because many people online spread so much misinformation about it that I’m sure most of you have already been mislead by a lot of arguments made around the subject. So what even is AI? As everyone knows, it stands for artificial intelligence, but that’s not exactly what it is, at least in the field of computer science. See, in computer science, AI is a very, very broad term that ranges from things like pathfinding algorithms (like the one you use for Google maps and stuff), puzzle solvers, and clustering algorithms, to the programs that people mainly associate with AI like LLMs (ChatGPT, Gemini, Copilot, etc.) and image generator models. They’re basically just algorithms designed to solve problems that were previously thought to require intelligence. Most “AI tools” that people think about fall under Generative Artificial Intelligence, or GenAI for short, as they are built on models designed to generate an output of data based on an input. Now, I could go into detail about the societal impacts of GenAI in modern society and the negative impacts of massive data centers running LLMs, but that’s not the thing I want to focus on today, especially since there is so much misinformation online about these things (seriously, the amount of times I’ve seen people post about the amount of water LLM data centers use without researching further or doing the math to see how exaggerated the figure is concerns me. I’m not denying that these data centers have severe environmental effects, but damn, do some actual research). No, the focus for today is on the idea of Artificial General Intelligence (AGI) which is the concept of AI that most people are familiar with from science fiction and movies, and why at the current rate, we are not going to achieve that very soon.
Artificial Neural Networks
Let me just cut to the chase. The tools that people call “Artificial Intelligence” right now, they’re nothing more than just a really complicated math function. That’s it. Remember in your middle school and high school math classes how you’d have a function f(x) = something something and you’d plot it on a graph? Take that to the extreme with many more inputs and a much bigger graph with many dimensions, and you have ChatGPT, the thing that a lot of people think is going to take their jobs. And as for training those models, remember in science class how you’d collect data in an experiment and then plot those points on a graph and draw a line of best fit? That’s basically how these “AI” models are trained. There’s some calculus involved, but we’ll get into that later, and that doesn’t take away from my point that these AI programs are nothing more than just really big math functions.
Some people hear “Neural network” in discussions about AI and think that it’s the computer simulating the neurons in the brain, but no, it’s literally just what I described earlier: a really big math function. Now, there are some approaches to neural networks that attempt to model some of the more complex functions of real neurons, but because of a thing called backpropagation (which I will get into later), the types of artificial neural networks used today are just really complicated math functions like I said.
So where does the name come from? Well, when we draw these neural networks, we represent the coefficients of the function as layers of nodes or like circles feeding information to every node in the next layer drawn with lines or arrows until we reach the output layer. This tends to look a lot like the neurons in the brain with the lines being like the synapses between them, but as we’ll get into later, it’s not quite that. Anyway, the input nodes are just the variables you put in the function, so like f(x,y,z) would have 3 input nodes in the input layer. Then, for each node in every subsequent layer, all the nodes of the previous layer are multiplied with the weight or value on the arrow pointing to that node and added together then put through an activation function (not explaining that one).
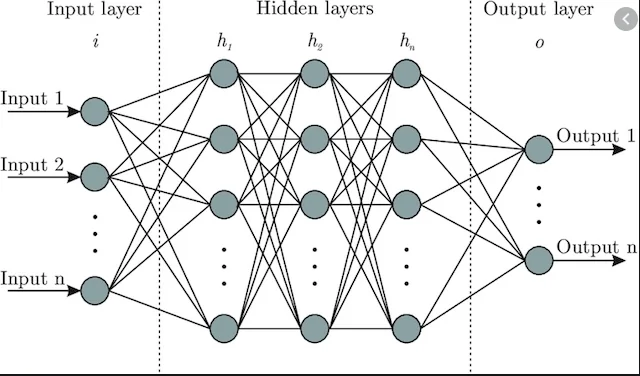
Because every node is connected to every node in the previous layer, we can represent all this multiplying and adding with matrix multiplication. GPUs are designed to do matrix math really fast, so that’s why demand for GPUs skyrocketed in recent years. Before we go on, I want you to note that information in a neural network only flows in one direction from the input to the output. There are some neural network architectures that involve flowing information backwards at some points for sequential data, but my point is that these things are designed to be used as math functions where you put numbers in and get numbers out.
And as for training, this is a little more complicated to explain in layman’s terms, especially since it took me a long time to grasp it, but essentially it’s just a bunch of calculus. You’re calculating the partial derivatives of the function and using it to make small changes to the coefficients. Yeah, that sounds complicated. Let me fix that by relating it to the science class thing. Imagine you want to find your y=mx+b function for the line of best fit for your data. You want that line to not just fit your data but also everyone else in the class who did the experiment. So first you start with random values for m and b and draw a line through your data. It’s a bit off, so you check how far off each dot is from the line and average it to make small adjustments to m and b. Then you do the same thing with the next batch of data from your classmate. You do this over and over again, even doing multiple passes over the same set of batches until you have a nice and neat y=mx+b function that draws a line that fits the data of everyone in the class. Then, you draw this line on data from another class to see if your function fits theirs too. Your class’s data was the training data and the other class was the testing data. That is basically what training is on neural networks.
The Limitations
So now you know that it’s all just a really big math function. It’s still impressive how just a bunch of numbers being multiplied and added together can achieve what we’ve done with AI tools. But there’s a polluting, heat-producing, energy hogging elephant in the room. Sure, you can do these calculations, but when you scale it up to the level of say a Large Language Model (LLM) like ChatGPT, you’re gonna be doing a lot of calculations at a very high speed and using up a lot of memory just to hold the values you’ve calculated. Sure, there’s technology being developed to make the whole pollution problem largely irrelevant like analog matrix chips and quantum computing, but we still have the problem that neural networks just don’t scale up very well. As you make them bigger and more complex, you just start to see some diminishing returns, to the point that just to achieve the cognitive ability of even the dumbest human, you’ve built a data center the size of a city. Surely if humans are able to achieve cognition at a minuscule fraction of the energy and resource consumption of a neural network, we must be going in the wrong direction.
Also, I would like to note that not all LLMs require these insanely large data centers to run for one person as some people are even able to run Deepseek on their own computers. Sure, it’s nowhere near the performance of something like the latest ChatGPT models, but it just goes to show that this technology does not need to be as harmful to the environment as it is.
I know I said before that the “neurons” in a neural network are not exactly analogous to real, biological neurons, but I’d like to bring back the analogy for this next point. I’m sure you’ve heard that you only use 10% of your brain. What that means is that at any given moment, only about 10% of all the neuron cells in your brain are being used. This is because using all the neurons just for the current situation would waste a lot of energy, so the brain and the rest of the nervous system try to find ways to connect neurons in ways that save energy while still accomplishing the same stuff. This is why when you learn, things start to feel easier over time since you don’t have to think as hard to do the same things. It’s like when you first learn multiplication, it’s hard at first because you have to keep adding up numbers a bunch of times, but eventually, after doing your times tables enough times, your brain automatically knows what number is the answer without you having to do the adding again. This is also how muscle memory works because sending signals to the brain uses up a lot of energy, so your nerves eventually learn to do those movements on their own (and also why once you develop muscle memory, you often forget how to consciously do those things).
Now, the thing is some older implementations of Artificial Neural Networks do emulate this behavior of using only 10% of the neurons, like in NeuroEvolution of Augmenting Topologies (NEAT); however, that’s not really a thing with the fixed-topology architectures we see in a lot of AI systems because all of the neurons are involved in every calculation. Actually, it’s even worse than that because sometimes trained networks will have certain neurons that don’t contribute but still get calculated because the computer doesn’t just skip over these values since it’s a matrix multiplication operation. This is why LLMs use up so much energy since they’re stateless machines that perform the same complex calculations for every input. I believe I’ve found a possible solution to this, but I’ll get into that later.
I mentioned the term “fixed-topology architecture” earlier. This basically means that the neural network has the same overall structure the whole time and the only thing that changes are the weights between the neurons. The neural network will only ever do what it’s designed to do and will only find patterns in the data that it is given. The interesting thing is that humans also have a fixed number of neurons. Neuron cells don’t divide like every other cell in the body, so from the moment you are born, you have the same neurons for the rest of your life. The reason why that’s not fixed topology is because of what I said before, that the connections between neurons develop over time. The different regions of the brain are kind of like the different components of a neural network in that each one has its own purpose, but the brain forms these architectures naturally and can even rearrange those regions into recursively smaller subregions whereas an ANN needs to be designed specifically for its purpose. ANNs don’t optimize their energy usage like the human brain does because they’re not designed to. They’re just meant to minimize the value of a function.
Finally, I would like to bring up the importance of sensory and physical interactions to human intelligence. I’m no expert on childhood development, but I do know that early on it is important for a child to learn from playing. By playing, I mainly refer to just interacting with the world around us in general. Our senses are the only ways for us to receive information about the physical world and so in early developmental stages of life, we spend it building up an understanding and intuition of our environment. We learn what things hurt, what things feel good, what happens when we do something, etc. And as we get older and gain more experiences, we learn how to connect these sensory experiences in abstract ways and gain the ability to form not just a model of the physical world but also more abstract concepts like language, numbers, art, stuff that we generally associate with the human experience. Also, this is where we get terms like “visual learner” or “audio learner” because we tend to think in terms of sensory experiences as those are the things that allow us to model our internal world. Me, I’d say I’m a haptic learner because I think in terms of physical movements and textures and vibrations.
For a computer to truly emulate human intelligence, it would have to be able to interact with the physical world so that it can understand how physical objects interact and develop an intuition for these things. There’s a popular argument in philosophy that all abstract thought is parsed as language and I’ve heard people online point to LLMs as proof of this argument since they can answer questions with only encoded language as input. I’ve always been opposed to that whole language argument, and I find that LLMs give more proof to my argument because they have shown many times to have a very limited understanding of the physical world. Without getting into too much detail, LLMs basically just encode words as vectors in high dimensional space and then adjust those vectors based on their relationships with each other and then produce an output based on what sequence of words make the most sense to follow up with. It’s very good at answering questions that have already been answered by someone before because its understanding of language is built on billions of examples of text, but its understanding of the physical world is based only on data from text. That’s why it can’t understand that a cup with no bottom and only a lid is just an upside down cup, unless it has trained on enough examples of people describing that exact thing.
We do see computers interacting with the physical world like with robots or cars with cruise control, but those sensory experiences are far different from human experiences. Sensory inputs with those computers are treated as just data to once again be used to minimize a loss function. It will learn to pick up patterns from that data, but it won’t build any complex understanding or intuition from it. It’s kinda like Plato’s Allegory of the Cave in that the computer only ever gets to see shadows of the physical world, but since it cannot directly interact with it, it doesn’t have a deep understanding of it.
A Possible Improvement
There are a lot more limitations with ANNs that I obviously haven’t brought up, but I think I’ve painted a clear enough picture about why this technology cannot lead to AGI, or at least without major costs. So then, what direction should we go in? Here, I propose an idea for an algorithm that addresses a point I made earlier about how the brain is so much more efficient than an ANN because it is capable of only using 10% of the neurons.
My idea takes inspiration from a game called Akinator: The Mind Reading Genie. If you’ve never played it before, it’s a game where you have to think of a character or famous person and then it will ask you a series of questions relating to that character until it guesses correctly. The algorithm it uses is based on a more traditional Machine Learning concept called decision trees. Decision trees are basically just a bunch of questions regarding your data and depending on the answer to the question, you then go to another question which leads to more questions until you find your answer. In the case of Akinator, every time you answer a question, it narrows down the possible answers and also the possible next questions. After enough questions, it will have a small enough list of names to make a guess. No neural networks are involved here, so the most expensive calculations come from just searching up specific data. After training on a lot of data, it starts to find the most efficient connections between questions to get to the most common answers faster.
Notice how similar this is to what I talked about with human neurons in that only a small percent of the system needs to be used for most of the time. This is the key to the algorithm I propose, but before we get into that, I need to explain Attention Mechanisms.
I’ll be honest, I still don’t have a good enough understanding of attention in machine learning, but I will do my best to explain it in a way that you can understand. In neural networks, an attention mechanism basically makes it so the system can look at how each thing of data relates to each other so that it knows which parts are most relevant to what it’s looking for, or what to pay attention to. In language models, we use this to make sure a model knows the meaning of a word with the context of the words around it.
I’m not gonna explain the math because even I barely understand it, but I will explain the basics. Imagine you’re trying to find a book in the library to answer a question you have. The library has no computer, so you can’t exactly search for your question, but you notice the library is sorted in such a way that books with similar concepts or keywords are on the same shelf, or at least close to each other. So using your question, you figure out what keywords to look for, and now you’ve narrowed it down to a few books that may contain the answers you seek. That is obviously an oversimplified explanation, but hopefully you see what I’m getting at.
Now, continuing from that analogy, sometimes you won’t get the exact answer you want, but you’ll find information that will help you get closer to the answer, so from what you’ve gathered, you modify your question a bit and then keep searching. After enough questions, you find your answer. And now, with every answer you seek, you get a little bit better at navigating the library until you’ve formed a set of questions that you can consistently ask to get you to where you need.
To avoid confusion for this next part, I’m gonna change a bit of terminology. I’m gonna use the term Multi-Layer Perceptron (MLP), the old terminology for Neural Networks for the smaller neural networks in this proposed algorithm. This is because the algorithm will be using these MLPs as an analogy for neurons instead.
Basically, this new algorithm combines MLPs with decision trees by trying to form a network of MLPS that lead into each other like a decision tree before coming out with an answer. In attention mechanisms, the question, or “query” is represented as a linear transformation which can just be a tensor or matrix (don’t worry, you don’t need to have passed precalculus to get all this). Same thing with the keywords and the contents of the books. The neat thing is that MLPs in their simplest form are just linear transformations, so we can have each “neuron” be an MLPs asking a question and the answer will either lead to the output or to another question if it decides it doesn’t have enough information. On the backwards pass, it will adjust the weights of the query matrices so that over time, it will form the best questions to find the correct output. Most importantly, the loss function will have emphasis on how many questions it had to ask to get to the right answer, so it will be incentivized to be using much fewer neurons and form more efficient connections over time, much like a real brain.
The problem is that I don’t understand enough about backpropagation yet to implement this system, and also, with what I do already understand about it, training will still be incredibly inefficient since you’re gonna need a lot of memory to load the training data in batches, but what it does mean is that theoretically, this algorithm becomes less computationally expensive over time, at least in evaluation, which means that the final product should only use a fraction of the computational power that a network of the same size would need.
Those of you who are more well-versed in machine learning might notice that this is similar to a Recurrent Neural Network (RNN), but that is not the case. RNNs use the same weight matrix for every input and just uses the previous hidden state to influence the next output. My proposed algorithm has several different weight matrices, but only the ones relevant to the input-output relationship get use in calculation. It’s not taking in sequential data necessarily, but rather it forms a series of queries that each have their own way of reading the data and tries to optimize the way these queries form.
This system could probably improve the performance of the massive AI models we have in place right now, but I don’t think this is the way to AGI. For that, we need to address the core problem I didn’t mention which is that computers are still built on digital architectures. AI models rely heavily on floating point operations which are extremely inefficient at the scale that they’re being used. Some companies have started investing into analog matrix chips which have their own problems, but are far more efficient and energy-friendly than GPUs in terms of tensor calculations. Also, a lot of research has gone into quantum computing which will definitely be the future of parallel computing in general. But for now, all this investment into fixed-topology MLP networks is just gonna make the AI bubble pop really loud.
Closing Thoughts
This whole post has basically just been an excuse for me to rant about my thoughts and feelings towards the current state of AI technology. I may do a follow-up either on my proposed algorithm or another rant more focused on the use of AI in society, but yeah for now these have been my thoughts. I do wanna start writing more of these posts again, but it’s just been so hard to balance school life, office life, and personal life that I just rarely find the time. I started writing this post over a week ago and I also have one in the drafts that’s been sitting there for several months now. Till then, keep thinking!
Addendum
I’m writing this quite a few weeks after I published this post because after working on the newly proposed architecture, I found that transformers (the neural network architecture used in LLMs and other advanced AI models) are in fact Turing-complete. In layman’s terms, this means that they are capable of emulating the operations of any computing machine, even itself. This still does not take away the overall point of the post because Turing-completeness is not enough to prove that a system is capable of emulating human thought. Maybe it is, but we don’t have enough understanding of the human brain to really confirm that, and even then, a system being Turing-complete does not mean it will be efficient.
Also, looking back on my proposed algorithm, it still has a lot of the same problems that I mentioned before, and I just didn’t think through it enough. I’m still going to try out my own stuff for fun, but I think it will be a long long while until someone truly solves it.